Preprocessing - Voorbewerking #
Voordat een retriever zijn werk kan doen, worden de documenten die je wilt doorzoeken (knowledge base), opgedeeld in kleine stukken, oftewel “chunks”, die vervolgens klaar worden gemaakt voor opslag in een vectorstore (een specifiek type database). Dit maakt het eenvoudiger om relevante informatie snel te vinden wanneer er een vraag wordt gesteld. De “chunks” worden vertaalt naar numerieke waarden in de vorm van vectoren en opgeslagen in de vectorstore. Dit wordt gedaan door een embeddingsmodel.
Intuïtie #
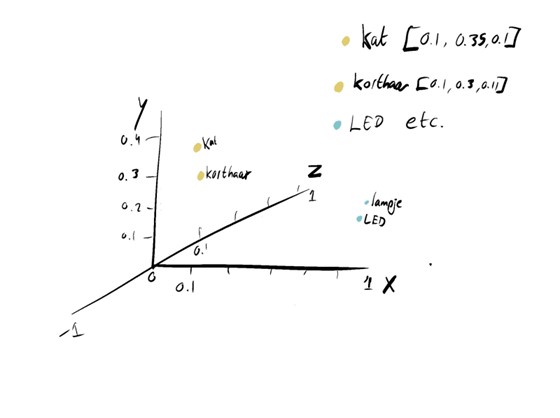
Stel je een virtuele ruimte voor in 3D. In alle drie de dimensies bevinden zich groepjes woorden die semantisch gezien dicht bij elkaar liggen, bijvoorbeeld een groepje met ‘lampje’ en ‘LED’ en eentje met ‘kat’ en ‘korthaar’. Die woorden kunnen coördinaten meekrijgen om aan te geven waar in die ruimte zij zich bevinden (namelijk langs een x,y,z-as). Het embeddingsmodel geeft deze coördinaten aan de woorden. Als men dit model dan gebruikt om te zoeken naar woorden die iets te maken hebben met ‘korthaar’, is het mogelijk dat er ook documenten naar voren komen met ‘kat’ en ‘hond’. Deze woorden liggen namelijk dicht bij elkaar in de virtuele ruimte. Het model hoeft alleen maar naar de dichtstbijzijnde getalreeksen te zoeken.
In de praktijk kan er op verschillende tekstgroottes (zin, woord, woorddeel, letter) numerieke coördinaten worden vormgegeven. Dit hangt af van de achtergrond van het model. Het is uiteraard niet precies zo simpel als beschreven. Daarnaast geldt bij dit soort modellen typisch niet een 3D representatie, maar een representatie van wel tientallen of honderdtallen dimensies. Dit is echter moeilijk voor te stellen.