Wat is RAG? #
RAG staat voor Retrieval Augmented Generation. Visueel gezien ziet een basis RAG-pipeline er als volgt uit:
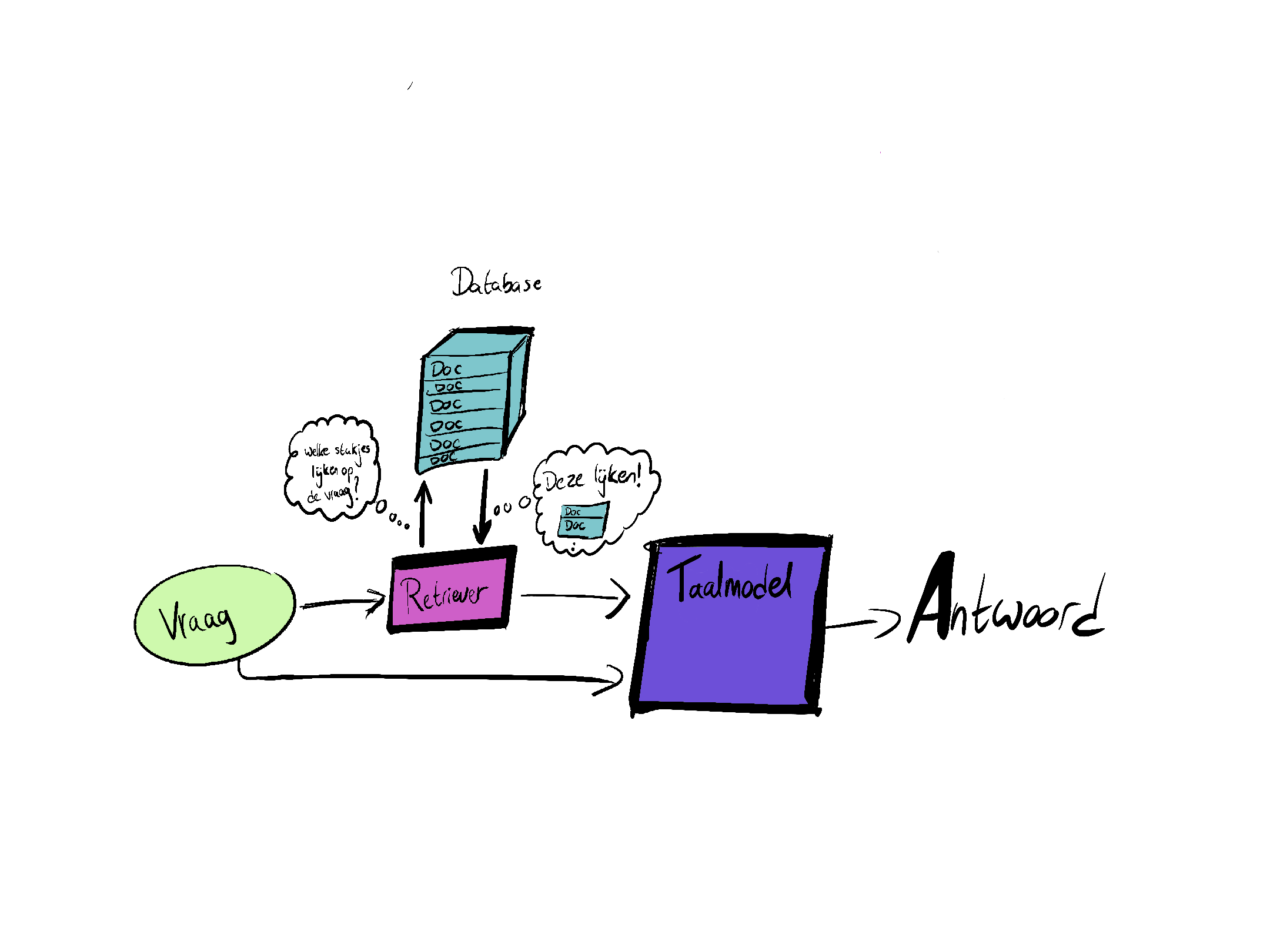
Preprocessing #
Voordat een retriever zijn werk kan doen, worden documenten opgedeeld in kleine stukken, oftewel “chunks”, die vervolgens klaar worden gemaakt voor opslag in een vectorstore (een specifiek type database) Dit maakt het eenvoudiger om relevante informatie snel te vinden wanneer er een vraag wordt gesteld. Lees meer
Retrieval #
Retrieval in RAG staat voor het ophalen van relevante informatie uit een database op basis van een query. Veelal gebeurt dit middels een voorgetrainde neural retriever (zgn. dense retrieval). Lees meer
Generation #
In de generatie-fase wordt, op basis van de relevante documenten, een antwoord op de query gegenereerd. Het taalmodel combineert de informatie uit de documenten om een goed onderbouwd antwoord te formuleren. Lees meer
Verdere cruciale onderdelen van een RAG-pipeline #
Evaluation #
Het evalueren van de gegenereerde antwoorden blijft een cruciale stap. Voor de kwaliteit van de retrieval worden andere evaluatiecriteria gehanteerd dan voor de kwaliteit van het gegenereerde antwoord. Voor RAG is het verstandig om zowel kwalitatieve, als kwantitatieve metrics te gebruiken voor het evalueren van de effectiviteit van een pipeline.