De resultaten van de eerste experimenten
October 2, 2024
De resultaten van de eerste micro-experimenten zijn een verkenning van de parameters en geen shoot-out van de verschillende modellen in absolute zin. Wel geeft dit ons een beginpunt van parameters om vanuit te gaan voor de ontwikkeling van de uiteindelijke pipeline voor de use case Kamervragen.
Experimentele set-up #
Knowledge base #
Er is getest met 1159 Kamervragen met beantwoorden als knowledge base. Dit zijn alle Kamervragen met bestandextensie (zoals .pdf of .docx) uit de API van de Open Data van de Tweede Kamer. Deze vragen bestaan uit volledige documenten met subvragen.
Queries #
Er zijn 52 bestanden op een willekeurige manier geselecteerd, waaruit steeds willekeurig 1 subvraag per bestand is geselecteerd om queries mee te doen. Dit is een statische set voor alle runs.
Retrieval parameters #
Chunk-size #
Om te chunken wordt er gebruik gemaakt van een QA-split (question-answer). De subvraag-subantwoord-paren worden op ruwe tekst gesplitst. QA-paren (subvraag van kamervraag met beantwoording) worden opgeslagen in de vectorstore en gematcht met input queries (enkel de vraag). De chunk-sizes die worden gebruikt zijn 128, 512 en 1028 tokens.
Token-length #
Dit is een arbitraire basisset van token lengtes. In de praktijk hield dit meestal in dat 128 werd overruled. Dit zou ook het geval kunnen zijn voor de andere waarden.
Observaties #
Deze token lengths werden in de praktijk op zinsniveau gesplit door de NLTK-sentence splitter. Dit betekent dat de getallen als parameters ingevoerd zijn, maar in de praktijk in flux door de werking van de gekozen tokenizer/splitter. Wij dachten echter dat dit zou gebeuren op basis van character level splits. Daarom is dit een onvoorziene parameter geworden die de ontwikkelingsrichting kan sturen. Het bleek in de praktijk dus niet om tokens te gaan, maar om zinnen.
Added context #
De context van chunks zou veel kunnen toevoegen aan de kracht van de retriever. In dit geval was het idee om de inleiding van de kamervragen als context mee te geven aan de chunks, omdat hier vaak contextuele inbedding van de vraag te vinden is.
Observaties #
In de praktijk is deze configuratie met context nog niet getest door onbekende redenen. We nemen dit mee in verdere ontwikkelingen van de pipeline, omdat we hier wel geïnteresseerd in zijn.
Performance metric #
Als performance metric om de ‘hitrate’ of ‘precisie’ te evalueren wordt de volgende formule gebruikt:

De UID (unique document ID) van het document van de oorspronkelijke query wordt opgeslagen en er wordt per query gekeken of het topantwoord uit het document van kamervragen verwijst naar het document met dezelfde UID.
Als standaard wordt er gekeken naar de 4 chunks die het meest op de query lijken (k=4). Voor de hit rate metric wordt gekeken naar de hoogste score, ofwel k=1.
Embeddingsmodel #
De volgende embeddingsmodellen zijn gekozen om mee te experimenteren:
BERTje en BERTje-sentence zijn gekozen omdat ze op Nederlandse data zijn getraind voor andere doeleinden. De andere drie modellen zijn gekozen vanwege de aanwezigheid in leaderboards en hun grootte.
Per configuratie (een combinatie van de parameters als beschreven in bovenstaande sets parameters), zullen er tien runs met 52 queries worden uitgevoerd. De performance wordt gemeten door per configuratie de runs samen te nemen en daarvan het midden te nemen. Dit vermindert in principe de onzekerheid door het willekeurig selecteren van de testset. Echter was de testset nu statisch, dus was dit minder van belang.
Observaties #
Jina gaf errors en heeft daarmee geen resultaten opgeleverd door onvoorzienbare modules die niet aanwezig waren. Daarmee is Jina buiten de resultaten gebleven.
Stella heeft geen errors vertoond in de test-logs, toch zijn er slechts twee runs voor medium aantal tokens geweest. Op een of andere manier zijn deze dus niet of beperkt opgeslagen. Daarmee is ook hieruit het resultaat preliminary.
Resultaten #
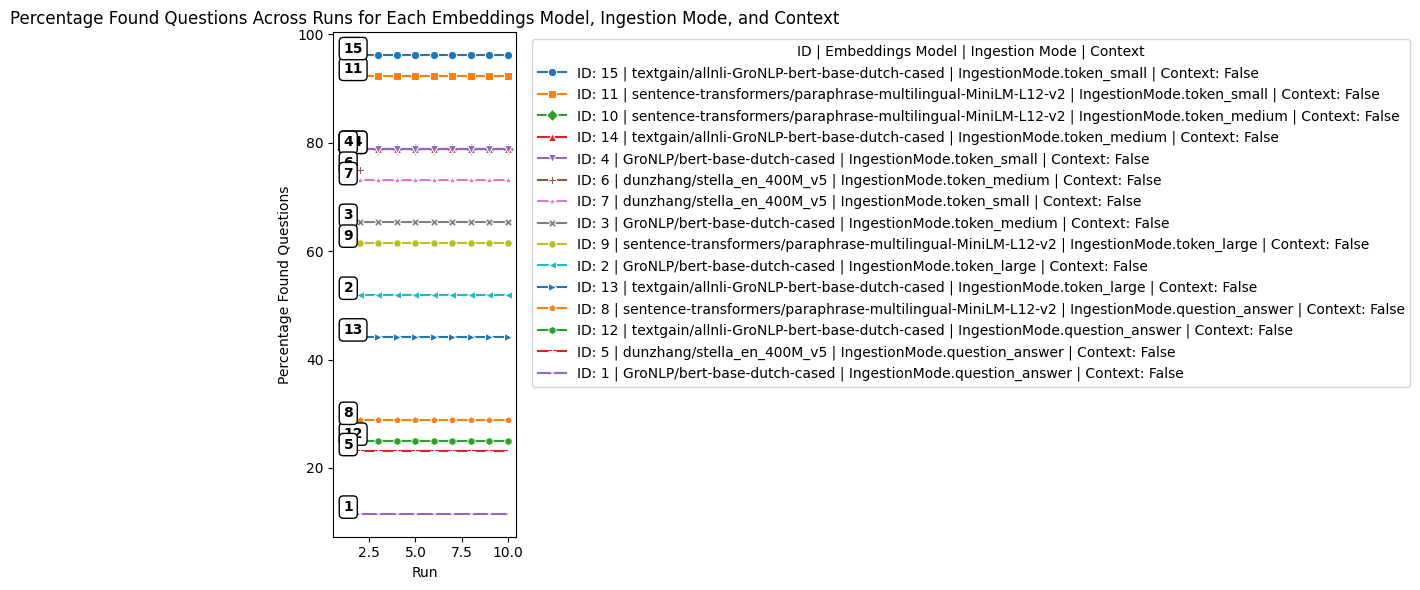
Voorzichtige conclusies #
We kunnen uit bovenstaande resultaten nog geen sluitende conclusies over parameters trekken omdat er te veel onzekere factoren over de werking van de pipeline bestaan. Wel leent het ons een beginpunt van parameters om vanuit te gaan voor de ontwikkeling van de uiteindelijke pipeline voor de usecase Kamervragen.
- We zien dat een ‘kleine’ token size (oorspronkelijk 128, maar niet altijd herleidbaar in de praktijk) vaak beter presteert dan de grote splits of de (waarschijnlijk kleinere) QA-splits. Dat zou kunnen komen doordat dit zorgt voor voldoende context van de vraag. Ondanks dat dit ontbreekt in geïsoleerde kamervragen, verwaterd er niet zoveel extra tekst dat de semantiek verandert.
- Er ontbreken configuraties waarbij context is toegevoegd. Daar zijn we nog steeds in geïnteresseerd, maar deze zijn door onduidelijke redenen niet getest.
- We zien dat een aantal sentence similarity modellen in deze configuraties beter presteren dan bijvoorbeeld de oorspronkelijke BERTje. Dit kan ook een aanknopingspunt zijn voor verdere ontwikkeling van modellen.
- De werkwijze en wat er precies onder de motorkap gebeurd is niet altijd uitlegbaar in de huidige situatie en in het tijdsbestek met de mensen die we nu hebben. Volledige meetbare ontwerpkeuzes binnen de huidige pipeline zijn daarmee nog niet binnen handbereik, maar er is een start gemaakt met het eigen maken van de pipeline.
Implicaties #
Onze volgende stap is het maken van een versimpelde en geüpdatete versie van de RAG-pipeline met nieuwere componenten. Deze moet wat sneller (anekdotisch) getest kunnen worden en transparanter/inzichtelijker zijn.
We gaan doorontwikkelen op basis van onze eigen bevindingen en ontdekte richtingen van ontwikkelen waaronder: experimenteren met hybrid-search, een kleinere chunk-size, context-toevoeging bij chunks en sentence-similarity-modellen. In eerste instantie BERTje-sentence en MiniLM.
Verder willen we kijken naar mogelijkheden om sparse retrieval methodes te integreren en in de nieuwere uitlegbaardere pipeline opnieuw verschillende testjes uit te voeren.